CEDAR in the GO FAIR Funder Study
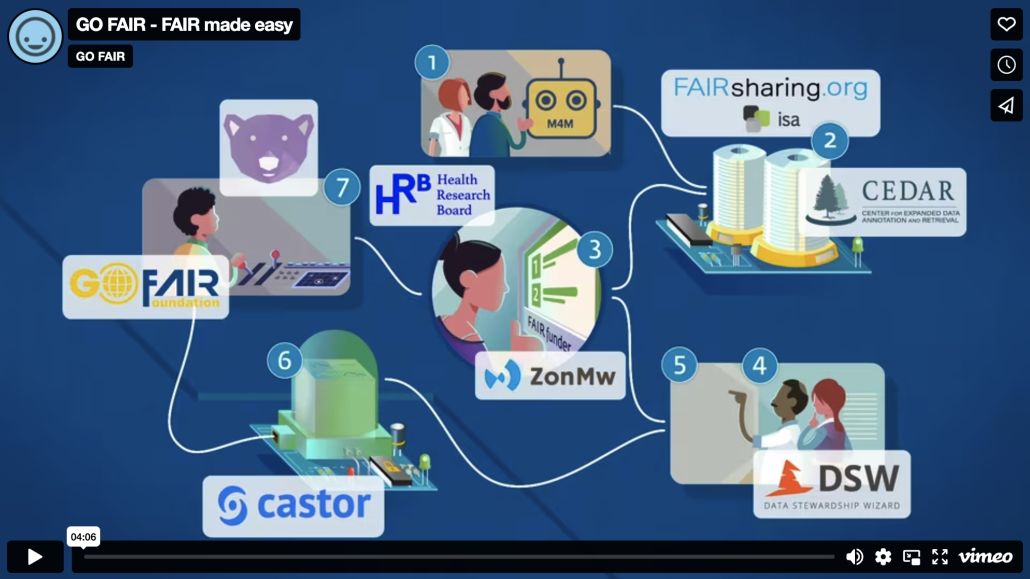
After providing contributions to the GO FAIR project over the last 18 months, CEDAR will be a significant participant in GO FAIR’s FAIR Funder Implementation Study.
This collaborative project will demonstrate a new level of integrated and FAIR metadata, making data projects funded by research agencies demonstrably more Findable, Accessible, Interoperable, and Reusable. As one of the founding collaborators, CEDAR has played a significant role in defining, describing, and implementing services that will improve metadata collection for funded research.
Read more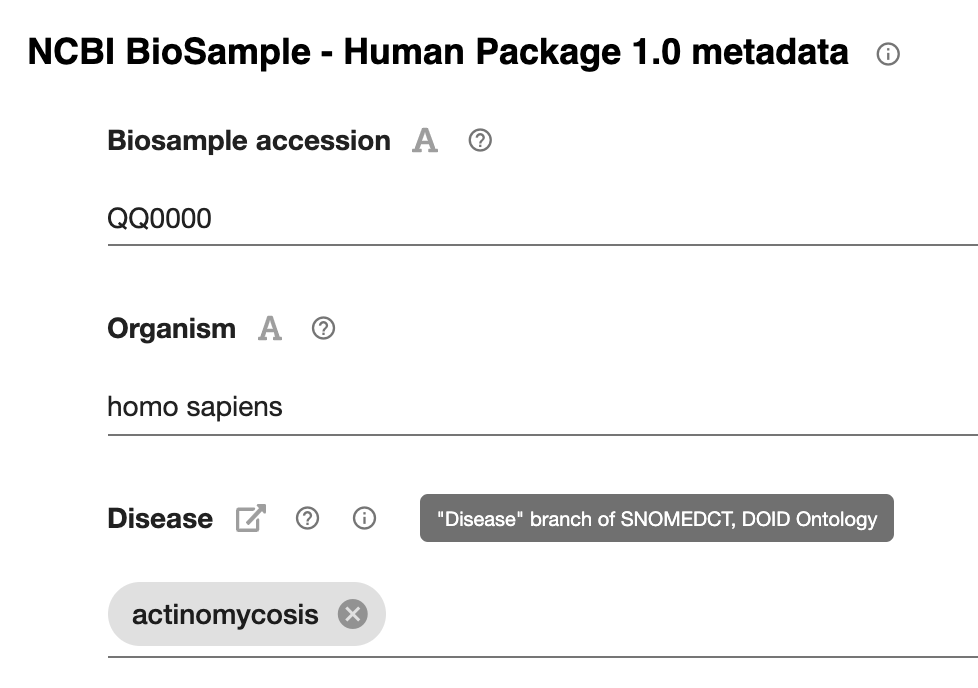 Did you ever want to show your template or metadata values to a colleague, without logging in? Do you want to view all your metadata on the web? Or maybe you’d like an IRI that anyone can use to see your work?
Did you ever want to show your template or metadata values to a colleague, without logging in? Do you want to view all your metadata on the web? Or maybe you’d like an IRI that anyone can use to see your work?