New Paper Accepted at AMIA 2026: CEDAR + AI for Automated Metadata Standardization
We’re pleased to share that a new paper from the CEDAR team has been accepted for presentation at the 2026 AMIA Annual Symposium: “Automated Standardization of Legacy Biomedical Metadata Using an Ontology-Constrained LLM Agent.”
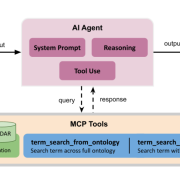
CEDAR’s core idea is that community metadata standards should be machine-actionable—encoded as templates that specify not just which fields are required, but exactly which values are allowed, drawn from controlled vocabularies and ontologies. This paper shows what becomes possible when those structured constraints are placed in the hands of an AI agent: messy, noncompliant legacy metadata can be cleaned up and standardized automatically, at scale.
The Problem: Millions of Messy Legacy Records
Public repositories are full of metadata authored before tools like CEDAR existed—idiosyncratic field names, free-text values, and inconsistent adherence to standards. That looseness is a fundamental barrier to FAIR data. Large language models can help interpret and rewrite such records, but on their own they don’t reliably produce the canonical terms a standard requires, and their training knowledge goes stale as ontologies evolve.
Read more