
The CEDAR proposal calls for a wide range of evaluation criteria for the CEDAR project. These criteria assess both the value of CEDAR’s recommendations and capabilities to users, and the usefulness and viability of the CEDAR project and software as a whole.
The CEDAR team will use various evaluation techniques, including data analysis of the resulting metadata, user experience evaluation, community evaluations, and adoption and access metrics. Objective evaluation will be aided by instrumentation of the CEDAR software throughout the life of the project, allowing ongoing data collection and cross-version comparisons.
The CEDAR project will focus at first on ImmPort and HIPC communities, which as members of the CEDAR team will work with us to identify issues and improve the system. As we gain experience, we will work with other BD2K centers and projects, and open our processes to the wider biomedical community.
ImmPort and HIPC Evaluation
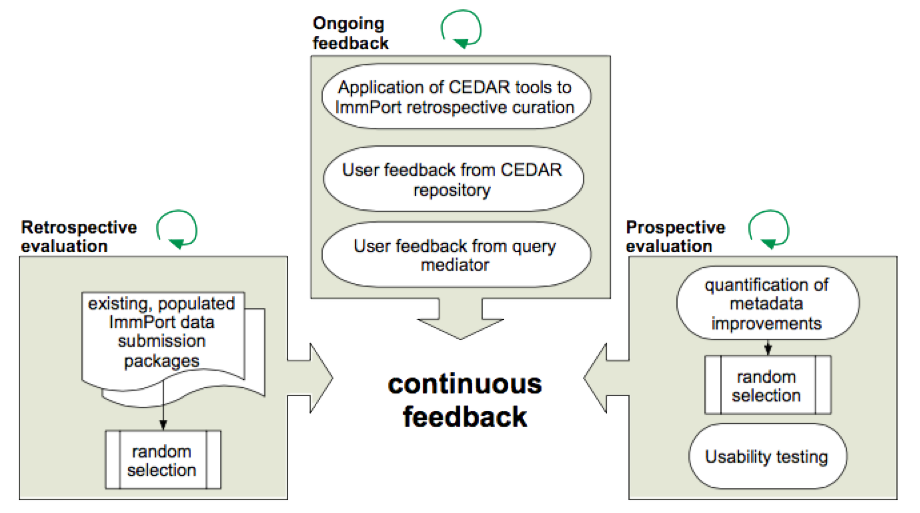 Our relationship with ImmPort and HIPC will give us a complete view on all facets of the research enterprise that in any way involve metadata—and the opportunity to continually assess the performance of our Center’s resources as our technology evolves over the course of the grant.
Our relationship with ImmPort and HIPC will give us a complete view on all facets of the research enterprise that in any way involve metadata—and the opportunity to continually assess the performance of our Center’s resources as our technology evolves over the course of the grant.
Our evaluation strategies for ImmPort/HIPC will assess the benefits of the CEDAR metadata acquisition tools. We will evaluate the accuracy and completeness with which metadata can be captured, and the overall ease of annotation using our technology. We will evaluate our tools both retrospectively, by re-annotating prior HIPC data submissions to ImmPort, and prospectively, by performing A/B testing of ongoing HIPC data submissions performed by the ImmPort curators. We will compare the data submissions that are performed using the CEDAR metadata acquisition interface, and the methods that ImmPort deploys currently.
Cross-Cutting Evaluation
We will evaluate user satisfaction will all aspects of our technology through usability analysis, instrumentation of our software, and formal and informal surveys of our users. We intend to assess not only the attitudes of our users toward our technology, but their opinions regarding metadata and the perceived burden of the requirement to annotate their experimental data.
As our system adds embeddable components that can be downloaded for use elsewhere, a helpful indicator of the usefulness and usability of those components will be their rate of adoption and frequency of use by our collaborators. We will instrument the tools to collect information on which components are downloaded and installed, which value sets they use, and which software components are accessing information from the CEDAR repository.
Template Authoring Evaluation
We will evaluate all components of our template authoring approach, including coverage of the metadata elements; usefulness and usability of the template repository; and effectiveness of our learning method to suggest value sets. We will use a variety of metrics to evaluate the template, including monitoring the traffic and the usage logs of the template repository. We will measure how often users have to repeat an unsuccessful template search, and how often they request new metadata elements. In collaboration with the BioSharing and HIPC teams, we plan to conduct observational studies as their scientists develop metadata templates, to assess task completion and other traditional usability metrics.
And, we will evaluate the effectiveness of our learning methods. In the laboratory, we will ask them to create template value sets manually, and compare these to the value sets that the CEDAR system suggests. In addition, we will present experts with suggested value sets, and ask them to evaluate whether or not the suggestions are useful. In actual operation, we will monitor the adoption of the suggestions by template authors, measuring the acceptance rate for the suggestions.
Metadata Authoring Evaluation
For metadata authoring, we will evaluate the metadata-acquisition interface itself, the learning methods for predicting interactive annotations, and effectiveness of structured metadata extraction, and the value of the system to request terms.
We will perform iterative design of our software by conducting usability evaluations throughout the project, using standard usability evaluation techniques, such as observation, usability questionnaires, and interviews.
We will evaluate the effectiveness of our predictions automatically by analyzing how often users followed the suggestions made by CEDAR, and manually by asking experts from among our collaborators to rank suggestions in specific annotation scenarios.
When we obtain annotations that we extract from unstructured or semi-structured data, we’ll compare with data sets annotated by experts. By running our pipeline on expert-labeled data we will be able to fine-tune and evaluate our learning system.
Finally, we will evaluate the usefulness of our term-proposal mechanism by measuring how frequently the proposed terms are adopted, and new terms get linked to existing terms.