
When a biomedical scientist needs to upload her data and enter corresponding metadata into a repository, she is faced with a formidable task. Not only does she need to navigate and fill out many forms to enter (and re-enter!) information, and make sure everything is cross-referenced correctly, but the metadata frequently end up stored in an ad hoc manner, in a non-standard format, and using non-standard terminology. As a result, finding or reusing the metadata, or understanding the underlying experiments, becomes extremely hard, if not impossible. But when the scientist uses CEDAR, our tools can make describing laboratory studies—or metadata for any other biomedical content—much easier.
Once an organization has created or selected a structured metadata template, investigators can describe their experiments, or other important research content, by populating those templates with descriptive metadata; and other scientists can search the metadata to access and analyze the corresponding online information. These processes are made much simpler by the guided interfaces, analytics-based suggestions and auto-completion, and the provision for drop-down controlled vocabularies wherever they apply.
Creating Metadata
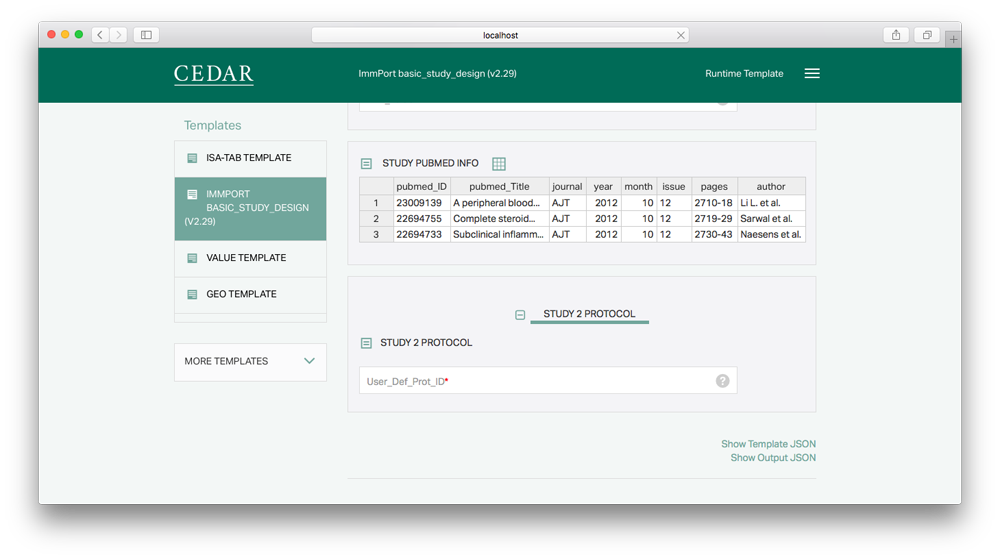 Our experience suggests that investigators require considerable assistance creating metadata. Accordingly, we are making it simpler for scientists to enrich their experimental data with metadata in ways that will ensure their value to the scientific community.
Our experience suggests that investigators require considerable assistance creating metadata. Accordingly, we are making it simpler for scientists to enrich their experimental data with metadata in ways that will ensure their value to the scientific community.
We apply many techniques to ease the work of entering metadata into form fields. For a user documenting a single resource using the CEDAR software, we make the software as simple as possible, with user tips and other cues. User entries are quickly verified according to the field type and other template constraints, so the user gets immediate feedback. But we want to make the user’s life much easier.
For example, of course we provide auto-complete capabilities that suggest possible content based on the user’s initial typing, and eventually we will suggest corrections for user errors. We also use machine-learning techniques to offer predictive metadata entries. Based on our analysis of similar fields, and even of multiple fields at once, we can put the most common entries at the top, so the user has the best suggestions at hand. Eventually we expect to pre-fill some fields if their content can be guessed with confidence.
And we're targeting even more sophisticated help. For example, we're working on analyzing the relative importance of related fields in predicting a given field, weighting the most important fields more strongly. And we'll make it easy for users to skip fields that are not relevant, or expand only the interesting parts of the template. And, someday we expect to use text analysis techniques to automatically extract structured metadata from narrative text, and also to drive the recommendation of ontology terms when templates (forms) are created. These analyses will be conducted over time, against a wide variety of data sets, and tested in real-world scenarios to ensure they optimize the user data entry experience.
We know metadata creation is not just about entering values into forms one at a time. Often forms can be populated by duplicating a previous entry, and changing one value; other times a spreadsheet view can make it very fast to create or review dozens of similar entries. And many biomedical informatics systems create large amounts of metadata automatically, which could be reformatted for automatic entry using an API and metadata specification. We've started working on many projects like these, and will make them available as soon as they truly help users create metadata.
CEDAR will provide all of these optimizations to maximize the speed and accuracy with which metadata can be created and edited. Our APIs, JSON-based metadata specifications, and spreadsheet-view user interfaces will make the metadata entry user experience what most users have always known it could be.
Updating Metadata: Changes and Enhancements
Descriptive metadata is not always correct or complete, and must be updated. We will provide the means to update metadata in our repository, as well as to suggest updates to metadata from other users. We'll even make it possible to share those (suggested or definitive) updates with the community and external repositories.
Obviously when changing previously entered metadata, many questions arise about authority and provenance. CEDAR will keep track of the provenance of entered metadata values, as well as the authority of that user or other users to change them; and will represent the status of any changed values (e.g., Changed, Suggested, or Rejected), along with the provenance of the changes.
By tracking these changes as event streams, we will have the flexibility to present them appropriately, including publishing metadata to the repositories of record for possible incorporation, and (where the data is public) for communities to leverage.
By automatically augmenting metadata in existing records, we will be able make those records more valuable. For example, we will evaluate previously developed technologies that extract key concepts from text materials like publications, and associate the publication to the records that led to it. With these automated approaches, we can provide significantly enhanced metadata for biomedical studies and other metadata descriptions.
Validating Metadata
One of the biggest challenges in analyzing biomedical big data is working with metadata errors, both small and large. CEDAR will contribute to better metadata by making it easy to specify and constrain the options for user data entry, which will help reduce a large number of errors and variations by expert and typical users alike. And by validating metadata entry immediately in the user interface, CEDAR can help prevent entry errors before they become real issues.
Because CEDAR will know a lot about not just the specifications and constraints, but also the typical and most common values for metadata fields, CEDAR can go further. By identifying metadata values that are highly unusual, CEDAR will identify fields and filled-out forms that deserve further review, or have similar types of mistakes. These can help metadata curators dealing with all types of metadata: reviewing single forms, or batches of metadata records, or even a whole repository of metadata. And as CEDAR grows smarter about different kinds of metadata, it will provide better validation and advice to both real-time users and post-entry data curators.
Just as CEDAR can facilitate the distribution of suggestions and augmented metadata to the community, it can facilitate review of existing metadata. And eventually, CEDAR can provide these services not just for metadata entered through the CEDAR infrastructure, but also for other systems that want to leverage CEDAR through API calls.
Searching CEDAR Metadata
CEDAR is not trying to keep all the metadata for the domains it addresses. For example, CEDAR is not the repository of record for metadata from biomedical studies. This is the responsibility of the primary repositories storing biomedical data, and of systems like DataMed as a data discovery index.
Instead, CEDAR is a research collection of metadata. Its primary objective is to improve metadata, and to enable researches to learn from existing metadata in order to improve metadata in the future.
Toward this end, the main CEDAR system collects the public metadata provided by users and public systems, since the more metadata CEDAR has, the better its suggestions and validation capabilities.
Note in particular that the CEDAR system at https://cedar.metadatacenter.org is not an appropriate place to enter information that must be kept confidential. In time we will explore CEDAR deployment to individual projects, to support their entry of confidential metadata within their own secure environments.
That said, the main CEDAR repository will contain a wide range of metadata for biomedical studies and related content. And it tries to associate all of the metadata with well-defined resources, either uniquely identified in the web, or uniquely specified by defined CEDAR templates. This will enable researchers to review the metadata, to use it to aid their own data research, and to analyze it with respect to common models and concepts.
In time, CEDAR will support an advanced search interface, based on common models defined in its templates, and on associations with unique web resources.
Analyzing CEDAR Metadata
The CEDAR team will publish user interfaces and APIs to support the export and analysis of CEDAR metadata. These capabilities will be described as CEDAR evolves, and should enable basic analysis for most kinds of research data addressed by the system.
The types of analyses that CEDAR will support can be found in Research Using CEDAR.
Publishing Metadata
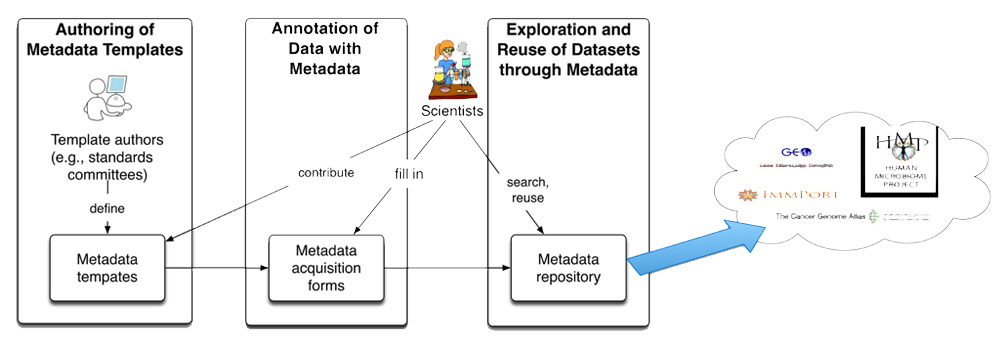 CEDAR realizes that users are not interested in entering all of their metadata twice, once for the target repository and once for CEDAR. The system will support publishing the metadata, and any links to the data sets, to commonly used target metadata repositories.
CEDAR realizes that users are not interested in entering all of their metadata twice, once for the target repository and once for CEDAR. The system will support publishing the metadata, and any links to the data sets, to commonly used target metadata repositories.
Already CEDAR generates a JSON-LD file that contains the metadata record in a well-described, easily parsed format. (The metadata is also available in a simplified JSON form, and as RDF triples.) This will enable many users to automatically convert the published metadata record into their needed format by writing their own conversion code, possibly reusing CEDAR-provided examples.
Right now CEDAR has created prototype publication pipelines for several NCBI repositories, and intends to release these soon. Over time CEDAR will build additional conversion examples, and will target direct-to-repository publication for the most important metadata repositories.