
 While good metadata is essential in finding, interpreting, and reusing data, the authoring of metadata is considered tedious and is often incomplete. Towards easing the burden of authoring high quality metadata, we have developed a data-driven framework to leverage associations between data elements to suggest context-sensitive metadata values. Post-Doc Maryam Panahiazar is working in the Dumontier lab to bring this technology to the CEDAR project. Using this approach, CEDAR’s context-aware recommendation engine facilitates metadata submission by suggesting possible value sets for the selected elements based on existing metadata in the repository.
While good metadata is essential in finding, interpreting, and reusing data, the authoring of metadata is considered tedious and is often incomplete. Towards easing the burden of authoring high quality metadata, we have developed a data-driven framework to leverage associations between data elements to suggest context-sensitive metadata values. Post-Doc Maryam Panahiazar is working in the Dumontier lab to bring this technology to the CEDAR project. Using this approach, CEDAR’s context-aware recommendation engine facilitates metadata submission by suggesting possible value sets for the selected elements based on existing metadata in the repository.
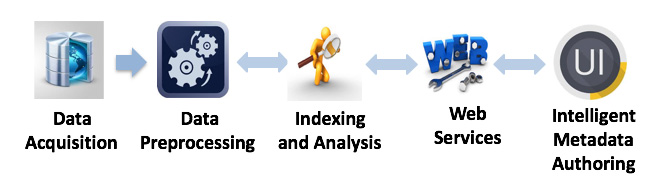
This system is designed around a basic workflow consisting of 5 steps: data acquisition , data preprocessing , indexing and analysis , web service, and metadata authoring user interface. The data submitter sees the results in the form of suggested responses for particular fields, based on the context (such as data submitter, and type of study) and on previously entered metadata. Moreover, when investigators have previously submitted metadata into repositories, investigator-specific learning will allow predicting the metadata entries based on their individual entries.
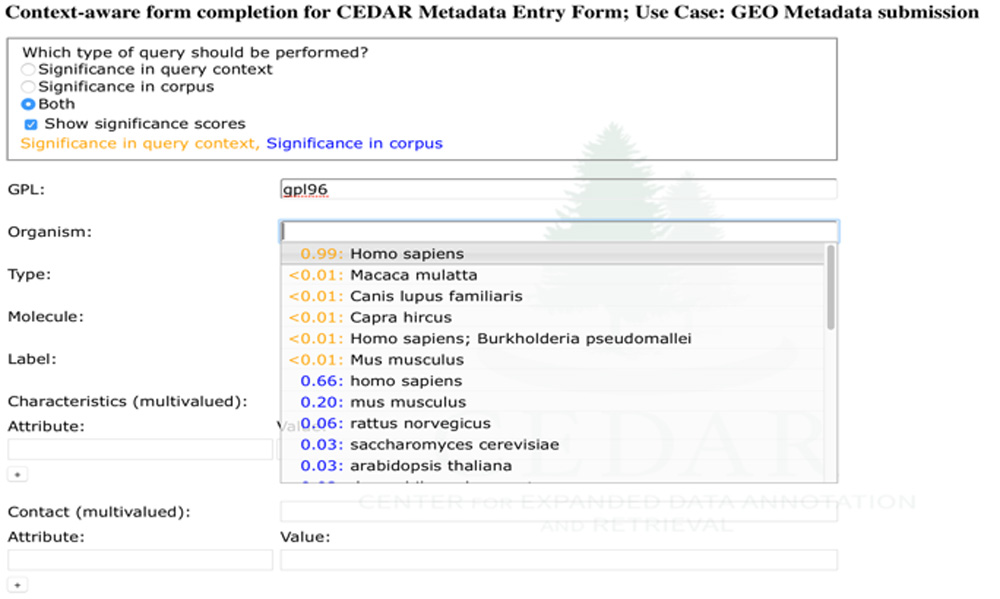 The data acquisition step of this workflow was first demonstrated using microarray annotations from the Gene Expression Omnibus (GEO), which provides a rich collection of public metadata for analysis. Data preprocessing, and indexing and analysis, was performed in an off-line system, and the contextual significance computed online without relying on pre-computed correlation scores. The initial web service demonstrated several features, including the initial suggestions of the most likely terms in ranked order, and the likelihood of those terms based on existing metadata. We continued using auto-completion to suggest the possible values for metadata elements in the user interface, to make the process of metadata submission faster and less error-prone for the metadata submitter.
The data acquisition step of this workflow was first demonstrated using microarray annotations from the Gene Expression Omnibus (GEO), which provides a rich collection of public metadata for analysis. Data preprocessing, and indexing and analysis, was performed in an off-line system, and the contextual significance computed online without relying on pre-computed correlation scores. The initial web service demonstrated several features, including the initial suggestions of the most likely terms in ranked order, and the likelihood of those terms based on existing metadata. We continued using auto-completion to suggest the possible values for metadata elements in the user interface, to make the process of metadata submission faster and less error-prone for the metadata submitter.
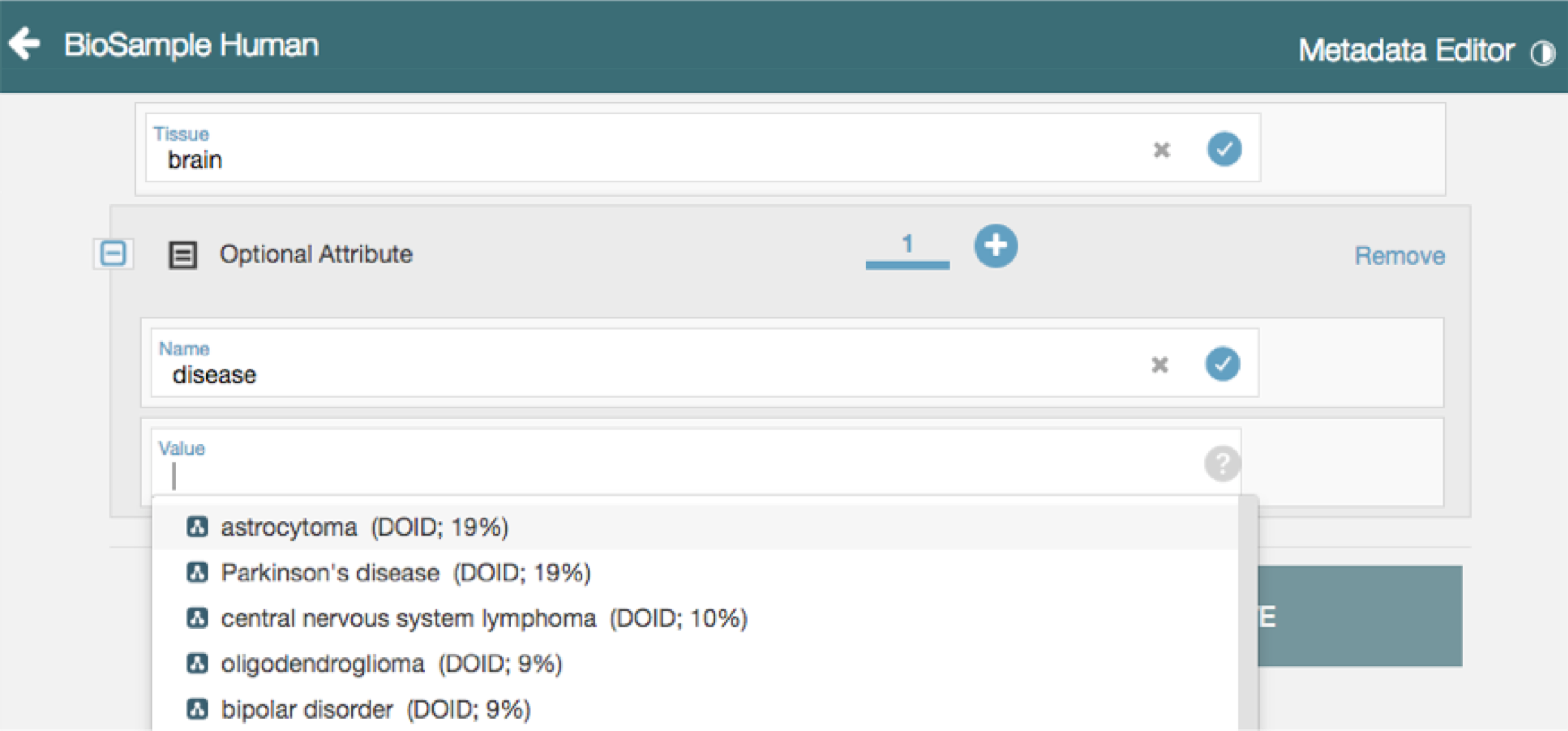 CEDAR has incorporated the initial technology into an intelligent authoring framework available in its production release. Shown in the screenshot at left, the system can recommend field values based on previously entered values, taking into account the values entered in other fields. Template creators determine which fields of a template are indexed for intelligent authoring, and suggestions grow in relevance as more data is entered using that template.
CEDAR has incorporated the initial technology into an intelligent authoring framework available in its production release. Shown in the screenshot at left, the system can recommend field values based on previously entered values, taking into account the values entered in other fields. Template creators determine which fields of a template are indexed for intelligent authoring, and suggestions grow in relevance as more data is entered using that template.
These services are equally applicable to the process of building templates. Suggesting typical value sets, based on existing metadata, will help template authors identify important value sets that appear frequently in the data, and let them choose whether to require that entries be made from those value sets for maximum interoperability.